Lecture 01 – Digital Systems Design
Ryan Robucci
1. References
- \(^\dagger\) Required Textbook for the course: A Practical Introduction to Hardware Software Codesign 1
- Patrick R. Schaumont, A Practical Introduction to Hardware/Software Codesign 2nd Edition, Springer (ISBN:978-1461437369) https://www.springer.com/us/book/978146143736
2. Outline
Today
- Analog to Digital Abstractions and Representations, and Granularity
- Digital General Purpose Computer and Systems
- Digital Representations
- Concurrency ad Parallelism
- System Performance: Amdals Law, Iron Law, Clock Speed (pipelining)
Next Class
- Verilog, an Event Driven Language to Model Digital Systems
- Concurrency Vs Parallelism
- Stratified Event Queue of Verilog
- Relate Representations: FSM, Timing Diagram, Circuit, HDL
- Mathematical Definition of Synchronous Finite State Machine (a Digital Circuit)
- FSM to Verilog Converter
- Clock Domain(s)
- Definition of a Clock Domain
- Significance of Clock Domains in Timing Analysis and Synthesis
- Simulating Digital Systems
- Zero-Time, Naive Unit-Delay, Precise Timing, Delta Cycles (VHDL)
- FSM Verification Coverage
- Non-Blocking Assignment and Non-Determinism
- Coding Rules for Single Clock Domain Synchronous Circuits (Synthesizable RTL code)
3. Analog and Digital Signals

- In signal processing, signals with time dependent variable are defined by a function, e.g. f(t) or s[n]
- for many application in signal processing in EE,
- time is the continuous ordered domain, as is the range
- after digitization (sampling and quantization) the signal is defined on a discrete ordered domain and the value range are also defined on a discrete ordered domain
- Analog Signal:
- continuous time domain, continuous value range
- for a spatiotemporal signal (like temperature in the US) the value can have a continuous time and continuous spatial domain
- Digital Signal:
- Digital, Temporal Signal (Time series): discrete-valued time domain, discrete-valued domain
- Digital, Spatial Signal (e.g. digital image): discrete-valued spacial domain (e.g. pixel location), discrete-valued domain
- Digital, Spatiotemporal Signal (e.g. digital video): discrete-valued spacial and temporal domain (e.g. pixel location and frame), discrete-valued domain
- Quantization:
- process by which values from a large set (such a as real values including 3.14159…) is mapped to a discrete symbol set
- bit-per-symbol: in digital computing, implied that the possible number of values is finite and a minimum of \(log_2 (\rm cardinality)\) number of bits is required to represent an isolated symbol
- Sampling (Time-Sampling): a process by which a signal is recorded at a discrete set of times, so that a finite number of values can be processed in each interval
- Ordered, Discrete Range:
- symbols have an order, and some are closer in that order than others
- in digital systems, binary codes are used to encode symbols
- an encoded symbol \(c\) is closer to \(d\) than it is to \(f\) — decisions and details of computations are based on this
- in an unordered domain, the symbols could represent label of characteristics that have no ordering amount them (r=red,s=small)
- the goal could be to simply record these characteristics (lossless encoding can achieve expected averages better than \(log_2 (\rm cardinality)\) for groups of values)
- the goal could be to make a computing machine that operates on these symbols and makes decisions and manipulates the values
4. Time Abstraction in Simulation

- Continuous time: SPICE simulation
- Discrete Event: only model lumped events and actions at certain points in time (not necessarily regularly spaced)
- Cycle-accurate: lumps events and actions according to bins of time defined by a clock. Certain events the happen on a sub-clock span like glitches may not be modeled. Model actions as happening either immediately at a clock edge or after some integral number of clock edges.
- Instruction-accurate: models functionality based on certain operations. All events at every clock cycle are not modeled, just the result of each instruction
- Transaction-accurate: used to model interactions between nodes of a system. The nodes can be hardware or software but the simulation model can be vary simple as compared to the implementation (example: modeling a hard drive)
5. Circuit Models and Abstraction
- Finite-Element Simulation:
- best effort to model a large system with many spatially localized approximations of physics (diff-eqn)
- often complex time-step step and convergence approach decisions, including time-rollback for corrections
- approximations of analog state variables and time as appropriate for a digital computer

- analog-circuit simulators:
- set of supported devices each with ports for connectivity and interaction
- netlist: instatiation of supported devices, the parameters for each instantiation (e.g length, resistance), and the connections amoung the instatiations
- use set of Closed-form, piece-wise equations (diff-eqn) for each device, e.g. capacitor, resistor, transistor
- though ports may be labels as input or output, there are many effects on the input based on the output
- minimal interaction amoung devices including KCL which is described the the connections in a "netlist"
- best approximations of analog states (e.g. voltage of a node)
- dynamic as opposed to fixed time-step is still common here
- hierarchy is common with use of "subcircuits" in SPICE-like simulators

- Switch level (Verilog):
- can support approximations of transistor models used in analog design with built-in primitives
- transistors: e.g.
pmos - resistors: e.g.
pullup - capacitors: e.g.
triregthat updates when driven and holds values when not
- transistors: e.g.
- for the sake of simulation efficiency: focus on limited set of states and limited set of possible interactions
- state values in the circuit nets (nodes) are constrained to an extremely finite domain (such as four possible values)
- Four-state:
- 0,1, undriven(Z), undetermined (X)
- requires 2-bits internally to represent
- Four-state:
- very small set of possible device output states and possible interactions ex: device driving strong1 and another driving weak0 -> 1 ex: device on driving 1 and another 0 -> X ex: one device on driving 1 and another not actively driving (Z) -> 1
- most devices are unidirectional so that output does not affect input
- circuits descriptions called netlists
- hierarchy is common, system is organized into modules that can be repeatedly instantiated (multiple copies)
- a flat netlist would only have primitives inside one system module
- can support approximations of transistor models used in analog design with built-in primitives
- Gate-level (supported by Verilog):
- uses models of basic logic gates like AND, OR
- four-state is still common, but faster simulators only use two-state (one bit per state)
- hierarchy is common, system is organized into modules
- Verilog has built-in combinational logic gate primitives,
- … but the implied leaf nodes are sometimes implied to be those from a cell library that is used to "substantiate" a netlist in simulation and many other processes involving electronic design tools
- a flattened netlist is one where the hierarchy is collapsed and one system module with only leaf cells (could be either Verilog primitives or cells from a cell library)
- Verilog does not have a primitive for a register, but provides facilities like behavioral code and "User-Defined Primitives" which can describe state transition tables

- Data-flow models (supported by Verilog):
expressions represent groups of gates assignment statements (look like equations)
a = c&m|8'b1000000; c = d & ~h;
- Behavioral code (supported by Verilog):
- use expressive languages (for..if..else) with code organized into processes or procedural code blocks that serve as models of various parts of a system
- small set of processes grouped along with some data flow descriptions placed into a module
- using these behavioral models, descriptions of specifications can be examined, but more importantly interactions of parts in a system can be studied in a system
- identified problems can lead to fixes in system architecture or changes in part specifications
- behavioral code is especially useful in testbenches for models of parts outside the "boundary" of a new design
- RTL code (supported by Verilog):
- RTL code sometimes called synthesizable behavioral code
- describes the flow of data among registers, particularly in one cycle of operation (one edge with a single clock)
- shares syntax but is uses a subset of behavioral code
- goal is to
- describe a deterministic update function for each register in a system
- …in such a way that a synthesis tool of choice understands how to convert it to a digital circuit
- 2 ↩️https://en.wikipedia.org/wiki/Semiconductor_process_simulation
- 3 ↩️found\ on\ en.wikipedia.org/wiki/CMOS \, By Abaddon1337 - Own work \, CC BY-SA 3.0\, commons.wikimedia.org/w/index.php?curid=19163930
- 4 ↩️https://en.wikipedia.org/wiki/Logic_gate
6. Representations of Digital Systems
Schematic:

HDL:
module timer(zero_next,rst, clk, q); parameter size = 3; input rst; output logic [size-1:0] q; output logic zero_next; input clk; logic [size-1:0] a; logic [size-1:0] _q; always_comb begin a = q-(size)'d1; if (rst==1'b1) begin _q = (size)'d1; end else begin _q = a; end zero_next = (_q == (size)'d0); end always @ (posedge clk) begin: blk1 q <= _q; end endmodule
Timing Diagram

Truth Tables: Combinational and Sequential
Combinational
- the output of combinational circuit is defined at any moment by the inputs
you can always determine the present output by knowing the present inputs and the function that relates them
a b y 0 0 0 0 1 1 1 0 1 1 1 0
Sequential
- sequential circuits have memory: state
- updates to memory and outputs can be based on state and/or input
- the state and output may be dependent on not only the immediate inputs but also the history of inputs
- state tables describe
- how state affects output
- how input affects output
- how state affects state
- how input affects state
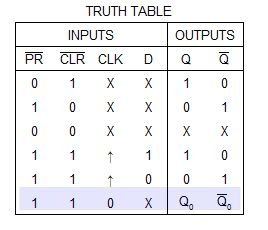
State Machine Diagram

7. FSM
A deterministic finite-state machine or deterministic finite-state acceptor is a quintuple \(\displaystyle (\Sigma ,S,s_{0},\delta ,F)\), where:
- \(\displaystyle \Sigma\) is the input alphabet (a finite non-empty set of symbols);
- \(\displaystyle S\) is a finite non-empty set of states;
- \(\displaystyle s_{0}\) is an initial state, an element of \(\displaystyle S\);
- \(\displaystyle \delta\) is the state-transition function:\(\displaystyle \delta :S\times \Sigma \rightarrow S\)
- \(\displaystyle F\) is the set of final states, a (possibly empty) subset of S \(\displaystyle S\).
- We are particularly interested in state machine descriptions since they provide a general mathematical model of synchronous digital logic by which we can understand the complexity of a functional test and validation
- They allow use to regularize testing and discussions on testing coverage
- state coverage: percentage of states tested
- transition coverage: percentage of state transistions tested
- Design using state machines concepts can also allow a computational task to be solved by a machine over multiple cycles time, with each state representing a manageable design task for the engineer
- i.e. can consider each state required and then independently design the desired input-output function for each state
8. Single-clock synchronous digital circuits
- Course textbook uses single-clock synchronous digital circuits using
word-level combinatorial logic and flip-flops
- These are built from components like registers, adders, and multiplexers
9. Cycle-based (RTL) Modeling
- Cycle-based hardware modeling is often called register-transfer-level (RTL) modeling because the behavior of a circuit can be thought of as a sequence of transfers between registers, with logical and arithmetic operations performed on the signals during transfers
- Basically, you describe what the contents of every register should be after every clock cycle based on the contents of registers before the clock transition
This description lends itself to implementation as synchronous logic through automated hardware synthesis
always_comb begin q = c+1; end always_ff @ (posedge clk) begin: blk1 c <= rst ? 0 : q; end

- does not describe all behaviors of digital logic, i.e. asynchronous logic, dynamic logic (multiple timed changes and interactions per clock cycle), multi-phase clocked-hardware, and hardware with latches (though latches can be model with limitations in some cycle-based simulators)
- does not by default include other sub-clock-cycle timing such as delays and thus would not model physical hardware and problems like race conditions or existence of sub-cycle glitchs
- Register Update Functions for Cycle-Accurate/RTL models
- update functions represent the desired update to be prepared and used to update each register
- in the vein of RTL, functions are derived from register values (others and self) as well as primary inputs
- primary inputs are the external inputs to the system
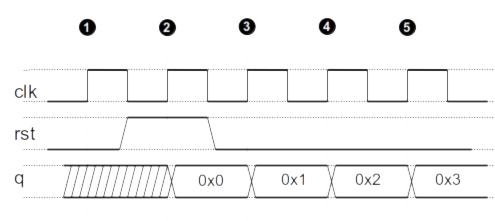

10. Sequential Code
- this concept will be borrowed for our behavioral code and RTL code to describe mathematical functions to update registers
- in Verilog called prodedural code
- We will hopefully explore use of HLS, which can also be mapped to hardware within limits and with expert suggestion
- The most basic software style is single-thread sequential programs.
- The control flow is naturally from one instruction to the next, except where jumps are specified
Subsumes a processor with some amount of registers, caches, RAM, ROM, arithmetic and other combinatorial modules, control logic etc… to implement an instruction set. Those instructions are called sequentially to move and process data.
- Does not include all programming paradigms, such as multi-threaded (which sometimes create an illusion of parallelism), objected oriented software, and functional programming
- Assembly and C have a strong correlation to the operations happening within the hardware (and give some sense of hardware utilization) while even higher-level languages tend to abstract the hardware further away.

11. Sequential vs Parallel vs Concurrent

- The function of a code written with a sequential coding style is
inferred by assuming that one line of code is executed at a time (in a
deterministic order)
- Execution order dependency (execution of operations require that operations have completed) (can be represented as a dependency graph)
- Can directly describe a cascade of operations where the output or effect of operating is the operating is the input prerequisite to another
- (A smart compiler and architecture may reorder execution if it determines that doing so is more efficient and does not change the result)
- Concurrency: concurrent code design allows a describing a function
by independent operations, where the order of execution between many
of them might not be defined
- Because of the non-deterministic order of execution, poor use of concurrency can lead to non-deterministic results (which may not be desired)
- The function of each concurrent actor/block might be described using sequential code
- Parallelism (or parallel execution) refers to simultaneous
execution, in which multiple operations are happening at the same
instant of time
- typically requires availability of additional hardware resources
- often useful when concurrency is appropriate (minimal order dependency among operations), see Amdahl's law later
12. Digital Systems Development
Digital System Design Leverages
- Abstraction
- efficiency gains from division of labor in engineering
- portability: high-level design can be ported to new implementation technology
- Modularity
- facilitates focus on a manageable chunk of specifications, design, testing, and debugging
- facilitates organized design,
- partitioning a design requires effort to design/document/generate interfaces, handshaking, synchronization/coordination
- Reusability
- Reusable designs can be easily leveraged for other design applications
- modular design may have more peices that can be reused as opposed to a monilithic design
- Programmability
- facilitates reuse of designs with minimal post-manufacturing changes
- Flexiblity: a design that supports more than the immediate application need or that facilitates adaption to differient appliation
- the ability of the platform to be adapted to different applications, is generally inverse to the efficiency (performance, size, energy,etc…)
- programmable means that the same HW part can be repeatedly repurposed, as opposed to one-time programmable or twice-programmable
- Field-Programmable (FPGA) : the reprogramming can happen in the deployed design itself
- Security
- Many security problems arise from abstraction — ignored details in component behaviors and interactions can be exploited
- Security usually has a cost (e.g. penalty to size, efficiency, functionality)
13. Dualism of Hardware and Software Design and Platforms
- Design Paradigm:
- Hardware: Primarily Spacial Decomposition
- Software: Primarily Temporal Decomposition
- Resource Cost:
- Hardware: more complex design usually means more area ( ▪️◾◼️⬛ ), and possibly time
- Software: more complex design takes more time to execute (⏲️++) , area is fixed by the hardware
- Flexibility
- Hardware: by design for flexibility
- Software: implicit
- Parallelism
- Hardware: implicit
- Software: by careful design
- Modeling vs implementation
- Hardware: commonly HDL, otherwise schematic, but this is not exactly the implemented hardware
- Software: modeling language is the implementation language itself (multi-node systems require some system modeling)
- Reuse
- Hardware: interface, conventions, and implementations vary making design reuse difficult. Some standardized interfaces (bus specifications and protocols) do exist
- Software: Common, many standard libraries and relatively easy to use interfaces
14. Concurrency vs Parallelism
- Concurrency: ability to execute simultaneous operations because the operations are independent (don't need the results of one to perform the other)
- Parallelism: ability to execute simultaneous operations because of use of or availability of hardware resources to do so.
- Hardware physically executes in parallel
- Multi-cycle computations may use the same hardware repeatedly over time
- Software can be modeled/described as sequential, concurrent, and parallel
- To speedup computation, must decide what parts of an algorithm can be parallelized
15. Application Example
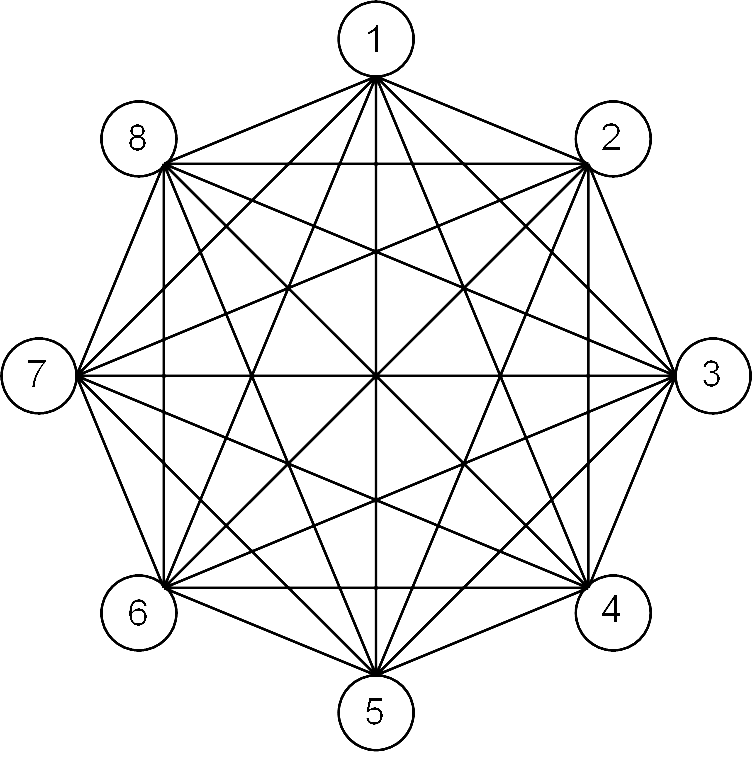
- Consider eight interconnected processors performing a summation of 8 numbers.
- We can assume an addition itself is a sequential operation.
- Summing 8 numbers on a sequential processor take 7 times longer than adding two numbers.
- In this parallel system, it can be done in 3.
Here is the schedule:
- The vertical axis is time
The horizontal axis is processor number

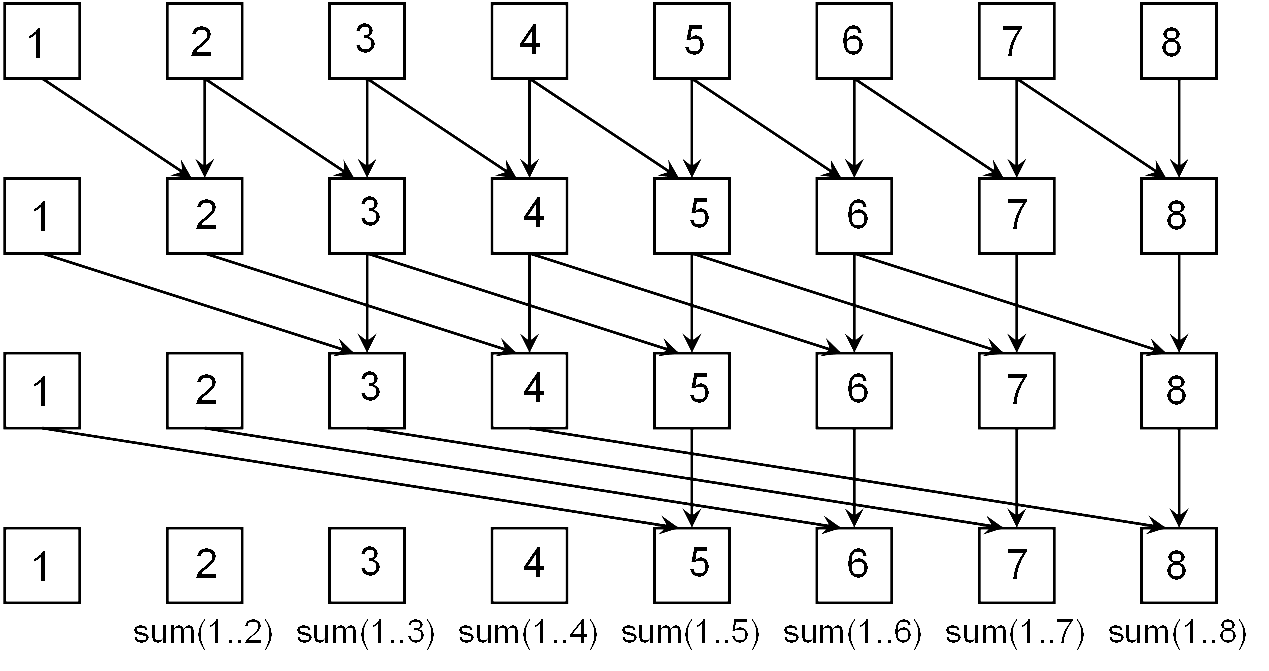
Retask unused resources deduplicate computations
- Unused parallel processors can be assigned new work while others
continue processing partial results.
- Computations can be organized so that partial results are shared instead of duplicated. Consider which of recomputation or communication is cheaper.
Example many different sums are computed:
16. Maximal Speedup of an Application Governed by Amdahl's Law
The maximal speedup is determined by the level of possible parallelism, but the complexity is in identifying what must be sequential vs. what can be parallelized, and how to parallelize. Algorithms may need to be reworked to leverage parallel computation.
A description can be found here: https://en.wikipedia.org/wiki/Amdahl%27s_law

17. Amdahl's Law
- Partition latency, \(T\),of a sequential algorithm (where latency is
the sum of latency of the parts) into two portions:
- \(T = T\cdot (1-p) + T \cdot (p)\)
- portion \(1-p\) that is non-optimizable sections of code
- portion \(p\) that may be optimized, such as through parallism, by a factor of \(s\) : \(T_{\rm new} = T \cdot (1-p) + \frac{T\cdot(p)}{s}\)
The RATIO of the old latency to the new latency can be called SPEEDUP, \(\mathbf S\):
\(\mathbf S = \frac{T_{\rm old}}{T_{\rm new}} = \frac{T\cdot (1-p) + T\cdot(p)}{T\cdot(1-p) + \frac{T\cdot(p)}{s}}= \frac{\cancel{T}\cdot (1-p) + \cancel{T}\cdot(p)}{\cancel{T}\cdot(1-p) + \frac{\cancel{T}\cdot(p)}{s}}\) \(\mathbf S=\frac{(1-p)+p}{(1-p)+p/s}=\frac{1}{(1-p)+(p)/s}\)
- Therefore, speedup is bounded by \(\mathbf S \le \frac{1}{1-p}\)
- Example: if your code spends 33% of the time in sequential code, the most that the code can be sped up by parallelism is 3x – even when 66% of the computation is executed in near-zero time
- Example with 1 s of computation, involving 16 parallelizable tasks
totaling 2/3 of the computation.

- Must find opportunities for parallelism: a key challenge is understanding what must be sequential and what can be parallelized, and what additional overhead might be incurred from communication to support parallelism
18. Compute Bound vs (Memory) Communication (I/O) Bound

- it is important to know true bottle-necks to focus design efforts and understand limits (scalability) of an approach
- a compute-bound implementation is limited by the availability and "processing power" of computational circuity
- e.x. solving an optimization problem with a modest number of variables
- computational resources can be upgraded to help performance
- faster on-chip clock speeds
- more on-chip hardware
- a communication-bound implementation is limited by the communication (I/O)
- if the limits is with memory communication, hardware upgrades (e.g. DDR4 \(\rightarrow\) DDR5), architecture, or algorithm changes may be required for improvement
- faster interfaces and memory speed (wider busses and/or more parallel memory banks)
- moving some memory on-chip can help to avoid off-chip memory access
- using burst transfers of continuous blocks data vs. individual transfers can be helpful, especially for off-chip memory
- changing algorithms to limit unnecessary repeated memory accesses or leverage burst block memory transfers
- communication can also be with respect to communication to other compute nodes
- specialized on-chip/on-die (e.g. dedicated buses, network-on-chip) and on-package communication hardware is critical if inter-node communication is the bottle-neck
- if the limits is with memory communication, hardware upgrades (e.g. DDR4 \(\rightarrow\) DDR5), architecture, or algorithm changes may be required for improvement
19. Semiconductor Design: PPA(S)
- in semiconductor design, PPA is the basis of design considerations
- Power [W]: energy used per second
- example 75W for a laptop processor
- Performance:
- most generally defined as number of operations performed per second
- examples:
- FLOPS: floating point operations per second
- FLOPs (lower-case s) is the plural of FLOP, a floating-point operation
- commonly characterized with a context-dependent subset of multiplication, addition, subtraction, and division
- the appropriate equation may vary by context, example: FLOPS = number of cores × \frac{cycles}{second} × FLOPs/cycle note that a processing unit that can perform one floating point operation per cycle in a design with a 1us clock cycle has the same performance as a design with a 100 Mhz clock with units that require a hardware resource to be allocated for 10 cycles of per operation
- Instructions per second (IPS) for CPU
- multiply accumulates (MAC) per second
- an accumulation of several multiplication results is history common in digital signal processing and even moreso now with new AI needs like CNN and vector and matrix operations vector dot product: \(\sum x_i y_i\) FIR filter: \(\sum c_i x[n-i]\) discrete 1-D convolution \(\displaystyle (f*g)[n]=\sum f[m]g[n-m]\)
- common to pair multiplication with following addition in hardware
- fused multiply-add (applies to fixed-point and floating-point) : combination of multiply and add fused into one optimized operation (suffers one rounding effect rather than two independent rounding)
- FLOPS: floating point operations per second
- examples:
- most generally defined as number of operations performed per second
- Area:
The area used by the design
- example: \(750 mm^2\) for a die
- for semiconductor design, this has signification impact defect rate, yield, and cost
- larger area may be synonomous with speedup where parallelism is possible
- larger area may be synonomous with power efficiency where running more circuits slowly in parallel is more efficient than fewer fast circuit
- Security: no clear quantifiable measure, but can be expected to come at cost of P/P/A
20. Systems Design: Size, Weight and Power (SWaP-C)
- Size-Weight-and-Power (SWaP) used to evaluate hardware systems that achieve a specification with a performance threshold (and cost threshold)
- SWaP-C: size weight power and co$t
- (SWaP-C2: size weight power cost and cooling requirements)
21. IC Design Size: Area-Yield-Related Cost
- IC markup cost is related roughly exponentially to area, because the probability of a defect-free IC drops exponentially with area
- Yield is the percentage of good ICs in a production batch

- Spatial Poisson Process wikipedia-spatial-poisson-point-process
- \(Pr\left\{N(B)=n\right\}=\frac{{\left(\lambda |B|\right)}^n}{n!} \times e^{-\lambda |B|}\)
- Chance of defect-free (n=0) and positive area, A, with defect density D0 (\(\lambda=D_0\)):
- Yield = \(Pr\left\{N(A)=0\right\}=\frac{{\left(D_0 \cdot A \right)}^0}{0!} \times e^{D_0 A}\)
- Yield = \(e^{-D_0 A}\)
- in some special designs, certain defects can be bypassed without losing the entire chip. This is a topic involving VLSI study.
22. Motivation for Chiplets
- When you discard a chip because of a defect, you want that chip to be as small as possible
- large design is broken into multiple ICs and packaged with specialized in-package communication
- compared to a large IC performance is sacrificed, but with much lower cost
- access to smaller dies also facilitates testing
- overview: https://www.keysight.com/blogs/en/tech/sim-des/eda/hsd/what-is-a-chiplet-and-why-should-you-care
23. Design Size and Architecture

- IC design is fundamentally 2D (VLSI)
- larger, highly interconnected designs become disproportional dominated by communication
- systolic arrays are designs with local connectivity to save on communication, but require specialize algorithms for use
- for very large designs, shared buses and network-on-chip hardware is common
- neuromorphic computing and compute-in-memory are related efforts to distribute and collocate small computations locally connected with memory (sometimes even leveraging analog computation)
- 3D-IC / IC-stacking is another effort to mitigate communication bottlenecks
- but the area of 2D provided the ability to cool, so 3D can present problems in thermal management and cooling